Application Results
This page showcases the results and screenshots from using the Financial Data Extractor application. The platform successfully extracts, normalizes, and compiles 10 years of financial statements from European company annual reports.
Home Dashboard
The home dashboard provides an overview of the system, showing available companies and quick access to key features.
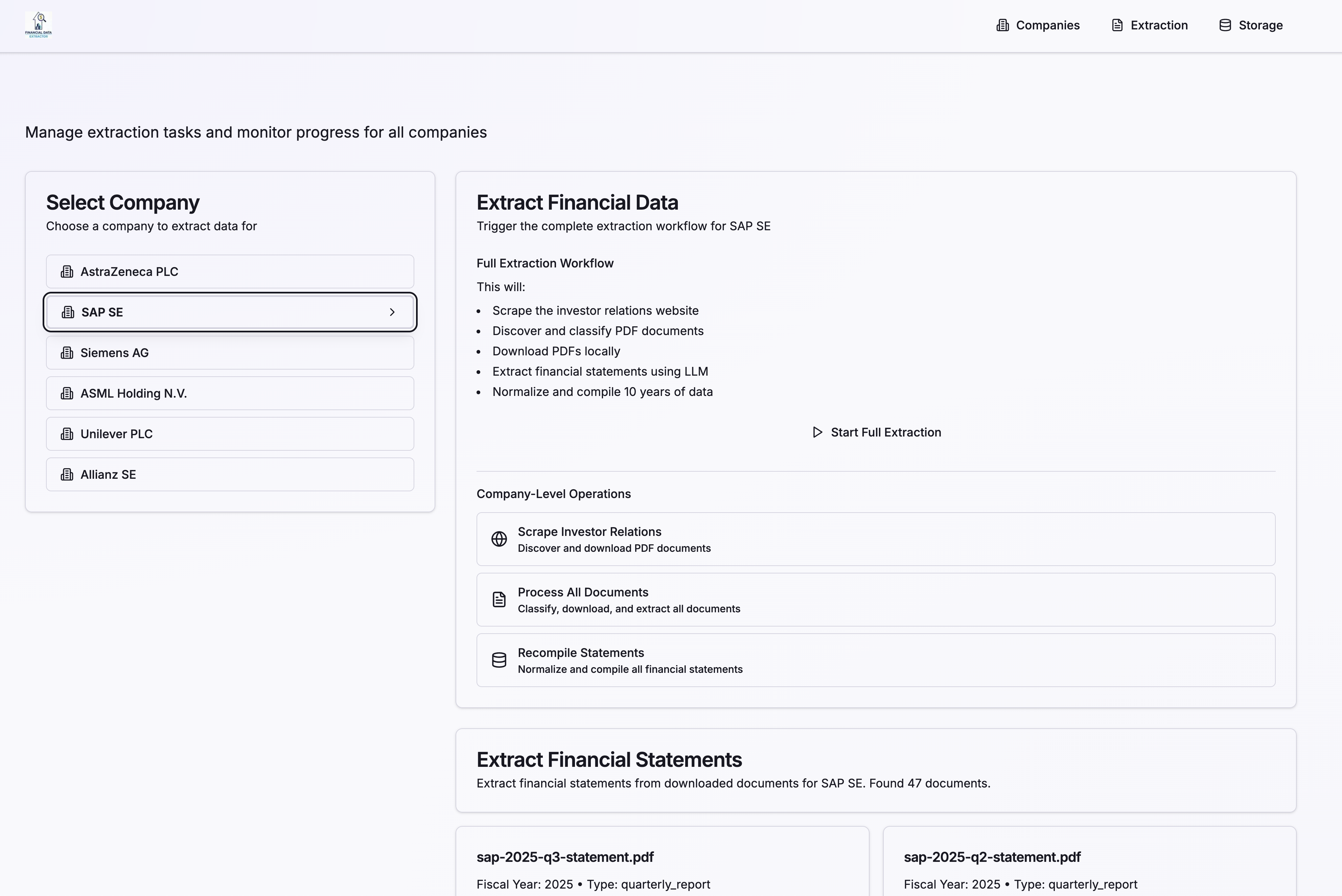
Extraction Process
The extraction interface shows the document discovery, classification, and extraction workflow. Users can monitor the progress of financial data extraction tasks in real-time.
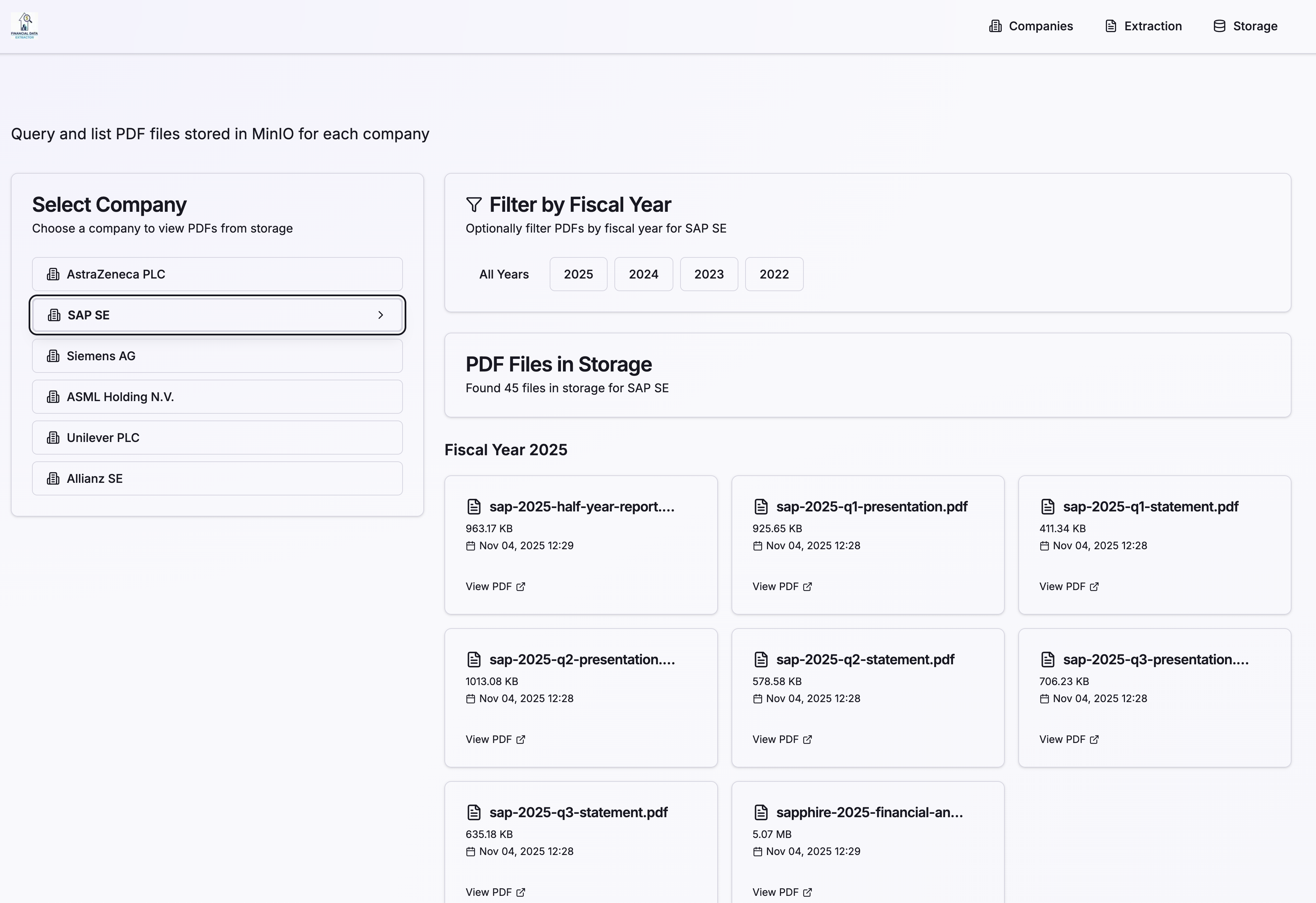
Storage Management
The storage management interface displays all downloaded PDF documents, organized by company and fiscal year. Users can view document metadata and access stored files.
Financial Statements
Income Statement
The compiled Income Statement view shows 10 years of revenue, expenses, and profitability metrics, normalized across multiple annual reports.
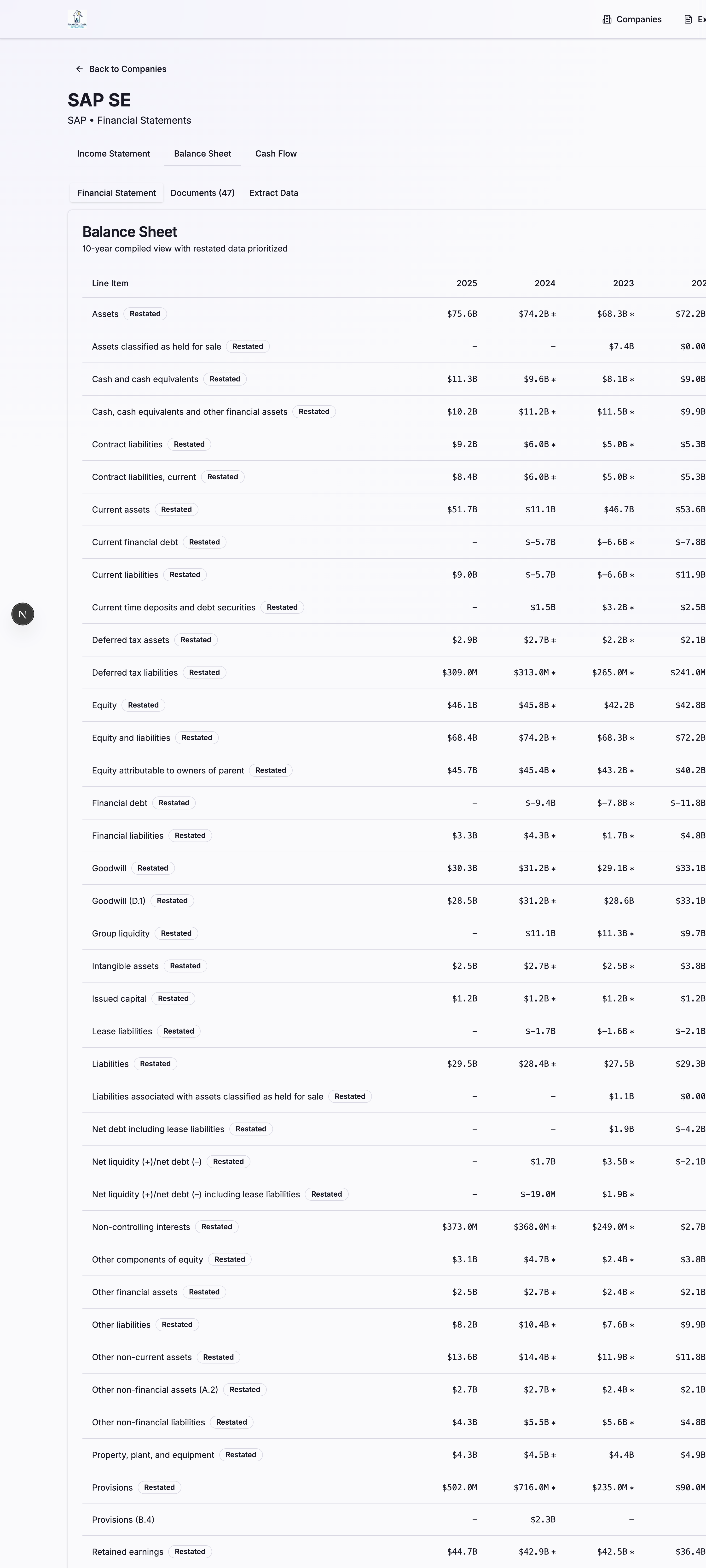
Balance Sheet
The Balance Sheet compilation displays assets, liabilities, and equity over 10 years, with proper normalization and deduplication of line items.
Cash Flow Statement
The Cash Flow Statement view presents operating, investing, and financing cash flows compiled from multiple years of annual reports.
Key Features Demonstrated
Data Normalization
The application uses fuzzy matching to align similar line items across different fiscal years, ensuring consistent presentation even when companies change their reporting terminology.
Multi-Year Compilation
All three financial statements (Income Statement, Balance Sheet, Cash Flow) are compiled into unified views spanning 10 years, making trend analysis straightforward.
Data Quality
- Confidence scores for each extraction
- Data lineage tracking (which report each value came from)
- Handling of restated data from newer reports
- Gap identification for missing years or line items
Real-Time Monitoring
The extraction process is fully monitored with real-time task status updates, allowing users to track progress through each phase:
- Document discovery and scraping
- PDF classification
- Financial statement extraction
- Data normalization and compilation
Next Steps
To see these results in action:
- Installation Guide - Set up the application
- First Steps - Run your first extraction
- API Reference - Explore programmatic access
- Architecture Overview - Understand how it works
Technical Achievements
The Financial Data Extractor successfully demonstrates:
- Automated Web Scraping: Discovery and download of annual reports from investor relations websites
- Intelligent Document Classification: Categorization of PDFs using LLM-powered classification
- Accurate Data Extraction: Structured extraction of financial statements using GPT-5 via OpenRouter
- Robust Normalization: Fuzzy matching and deduplication of financial line items
- Multi-Year Aggregation: Compilation of 10 years of data with proper handling of restatements
- Modern UI/UX: Clean, responsive interface built with Next.js 15 and TailwindCSS
For more information about the technical implementation, see the Architecture documentation.